

Все вы знакомы с давлением, которому подвергается свиноводческая отрасль из-за работы с питательными веществами, а теперь и с ее предполагаемым влиянием на климат. Мы в значительной степени зависели от технологических достижений в области генетики и питания, чтобы добиться повышения эффективности и чтобы уменьшить эти воздействия, но вскоре может стать доступным целый набор инструментов управления, использующих данные о фермах, которые помогут извлечь дополнительную прибыль.
Мы все осознаем, что на наших фермах происходит гораздо больше, чем мы в настоящее время можем оценить с помощью типичных показателей программного обеспечения, таких как среднесуточный привес и конверсия корма и что влияет на прибыльность и использование ресурсов. В некоторых случаях информация, скрытая в типичных усредненных значениях этих показателей, если она будет обнаружена на раннем этапе, может значительно помочь в возможности как диагностировать ключевые факторы, снижающие прибыль (узнать, что они из себя представляют), так и предвидеть предстоящее сокращение прибыли в ближайшем будущем, которого можно было бы избежать. Основная проблема заключается в том, что большая часть снижения прибыли (упущенная возможность) вызвана субпопуляциями (часто относительно небольшими) всего поголовья.

Субпопуляция — это, по сути, любая определенная подгруппа свиней в более крупном поголовье. Скажем, у вас есть теория, согласно которой большой процент поросят, чей вес при рождении ниже среднего и которые рождены от свиноматок с третьим опоросом и меньше, подвержены более высокому проценту неэффективной работы вакцин при вакцинации в обычное время обработки вместе с остальными поросятами. Что, если бы вы могли идентифицировать их и вакцинировать через день или два и полностью восстановить эффективность вакцинации?
Здесь мы имеем несколько субпопуляций, в том числе вес ниже среднего в помете, рожденные от свиноматок с тремя опоросами и меньше и вакцинированные через определенный диапазон дней после опороса. В настоящее время коммерческие фермы, вероятно, могли бы идентифицировать этих животных в корпусах опороса, но это сложно, дорого и маловероятно отслеживать этих животных на протяжении всего производства, для того, чтобы оценить их результаты и то, имеет ли они достаточное влияние на прибыль и оправдывают ли действия по предотвращению потерь?
Субпопуляции часто определяются через диапазон веса, скажем, все в корпусе между 30-50 кг. Или их можно определить как всех животных, которые имеют общие характеристики, такие как вес при рождении ниже среднего в помете. Во втором случае распределение веса этих животных будет смешано с другими животными, не обладающими определением группы. Выявление их только с помощью данных убоя, безусловно, может быть сложной задачей, а когда это возможно, требуется сложное программное обеспечение. Одним из сложных факторов при работе с подобными субпопуляциями является идентификация отдельных животных, а затем проведение периодических измерений по мере их роста, чтобы можно было оценить экономический эффект. Хотя это иногда делается в корпусах, оборудованных для проведения экспериментов, обычно это слишком сложно и трудоемко в коммерческих условиях.
Все это меняется, и скоро у нас появится возможность определять подгруппу, а затем эффективно отслеживать ее с помощью ваших данных. Как я подозреваю, вы знаете, что есть довольно много людей, работающих над способами идентификации животных и пассивного измерения в момент их роста, не беспокоя группу, разделяя животных по весу или иным образом. Когда вы взаимодействуете с группой, например, входите в станки и взвешиваете их несколько раз, вы рискуете негативно повлиять на результат всей группы, вызывая стресс у животных.
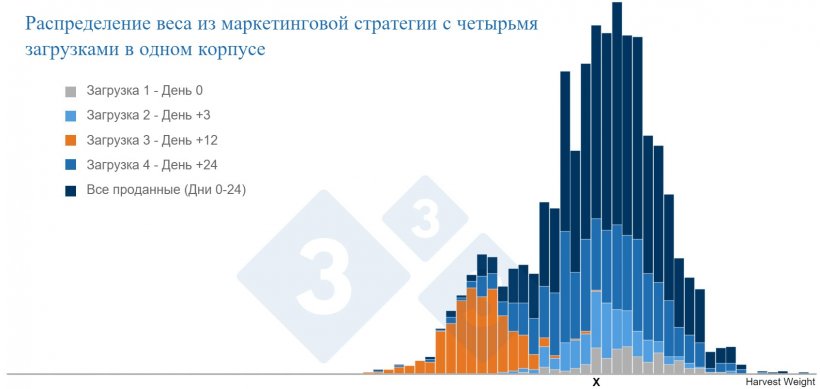
Отчетливо видно, что животные с массой «X» принадлежат к 4 различным субпопуляциям.
Обратите внимание на график. Темно-синие полосы представляют всех животных, продаваемых на рынке, а другие цвета представляют собой субпопуляции, продаваемые при разном количестве дней кормления. Обратите внимание на X, расположенный на оси веса. Отчетливо видно, что животные с массой «X» принадлежат к 4 различным субпопуляциям (проследите прямо от X по цвету). Если бы мы не добавили дополнительную информацию о дате продажи, были бы доступны только полосы синего цвета (все животные). Это иллюстрирует дефицит информации, который может возникнуть в результате слишком большого «усреднения» или консолидации характеристик. В следующий раз мы рассмотрим, как разделение ваших данных по кластерам характеристик на подгруппы может помочь в диагностике проблем и разработке планов действий.
